Ah, image processing...a beautiful art form that has yet to be fully tapped. There are so many things that can be done with image processing: Beautifying a picture, edge detection, object recognition, etc. etc. However, those concepts can be EXTREMELY difficult to understand without some very basic foundations. That's the point of this lovely article.
The Convolution Matrix (Kernel)
In the most basic sense, a convolution is simply a multiplication of two functions across an infinite difference domain. Below is the definition of the convolution:
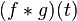 |  |
This can be difficult to envision with complex functions but becomes extremely useful in engineering most notably with Transfer Functions. Below are two great examples of how convolution works visually with two functions:
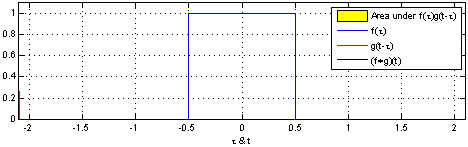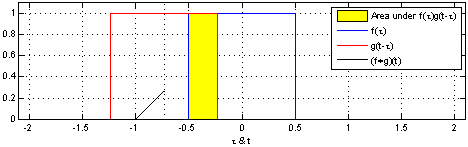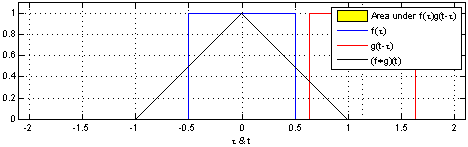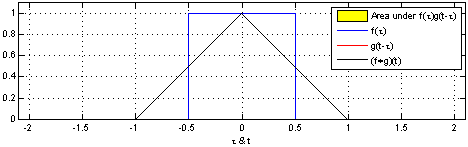

So how do we use it for images? How is it even useful?
Well let's consider the images above and how the Outputs (black) are created. As the transfer function (Red) translates over the Source (Blue) you can see that the source will change as more iterations of Tau occur. Why is this occurring? Basically each point on the source is having itself multiplied by each point on the transfer function and summed up. The reason it may not look this way above is simply because t & tau are plotted on the same axis.
So now imagine the flow above is an image row and the red box is a matrix we swipe across the image performing a convolution. As the box travels across the image we are wanting to process, we're getting a result back (black). This is how the Convolution Matrix (or kernel) for an image works.
A convolution matrix is an odd matrix (matrix with odd dimensions 3x3, 5x5, 7x7, etc) that sums the intensities of surrounding pixels based on the numerical weight
value in the matrix row/column. The center value of the matrix is the primary pixel intensity weight.
The formula for a 2D convolution is shown below:
where x is the input image and h is the transfer function (convolution matrix). It is harder to depict how this matrix flows exactly over the image, basically the matrix is flipped in the x/y direction and multiplied and accumulated for the pixel intensity. Take a look at this example. They did a better job than I could have done visually explaining it.
So if you follow the equation above (using the link example for reference) you should easily be able to implement a basic convolution mechanism.
Kernel Filters
So now that you have the equations, how can we really use them? Well these are used in a large variety of ways. But many common filters that you see in different image processing applications use this basic concept to get the different effects. In the table below I have listed some common examples of kernels used and I have applied them to the moon image below so that you can see how it affects an image in different ways.

Original Image
| Identity |  | |
| Edge Detection 1 |  |  |
| Edge Detection 2 |  |  |
| Sharpen | 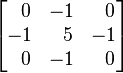 |  |
| Gaussian Blur (Approximate) |  |  |
Conclusion
As you might can see, you can do pretty cool things with a Convolution Matrix. In general, convolution(s) are a powerful mathematical tool in any arsenal. (I may need to show how it's used in other fields).
I performed these convolution(s) using GIMP. Under the "Filter->Generic->Convolution Matrix..." menu item. Try it for yourself and see how cool it is.
If you have any questions, as always, hit me up!